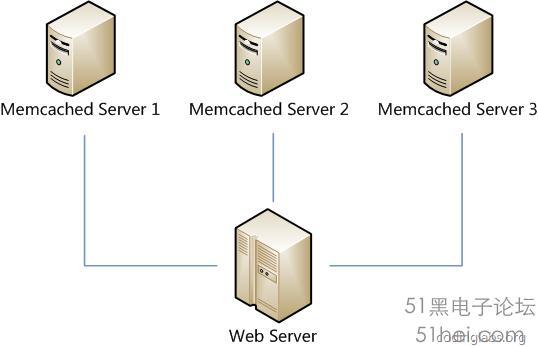
很顯然,最簡單的策略是將每一次Memcached請求隨機發送到一臺Memcached服務器,但是這種策略可能會帶來兩個問題:一是同一份數據可能被存在不同的機器上而造成數據冗余,二是有可能某數據已經被緩存但是訪問卻沒有命中,因為無法保證對相同key的所有訪問都被發送到相同的服務器。因此,隨機策略無論是時間效率還是空間效率都非常不好。
要解決上述問題只需做到如下一點:保證對相同key的訪問會被發送到相同的服務器。很多方法可以實現這一點,最常用的方法是計算哈希。例如對于每次訪問,可以按如下算法計算其哈希值:
h = Hash(key) % 3
其中Hash是一個從字符串到正整數的哈希映射函數。這樣,如果我們將Memcached Server分別編號為0、1、2,那么就可以根據上式和key計算出服務器編號h,然后去訪問。
這個方法雖然解決了上面提到的兩個問題,但是存在一些其它的問題。如果將上述方法抽象,可以認為通過:
h = Hash(key) % N
這個算式計算每個key的請求應該被發送到哪臺服務器,其中N為服務器的臺數,并且服務器按照0 – (N-1)編號。
這個算法的問題在于容錯性和擴展性不好。所謂容錯性是指當系統中某一個或幾個服務器變得不可用時,整個系統是否可以正確高效運行;而擴展性是指當加入新的服務器后,整個系統是否可以正確高效運行。
現假設有一臺服務器宕機了,那么為了填補空缺,要將宕機的服務器從編號列表中移除,后面的服務器按順序前移一位并將其編號值減一,此時每個key就要按h = Hash(key) % (N-1)重新計算;同樣,如果新增了一臺服務器,雖然原有服務器編號不用改變,但是要按h = Hash(key) % (N+1)重新計算哈希值。因此系統中一旦有服務器變更,大量的key會被重定位到不同的服務器從而造成大量的緩存不命中。而這種情況在分布式系統中是非常糟糕的。
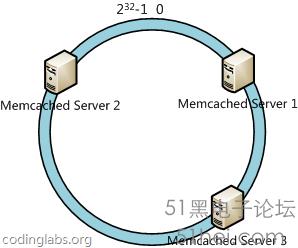
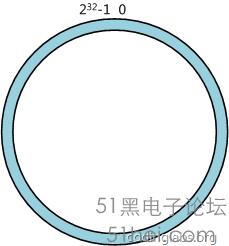
一個設計良好的分布式哈希方案應該具有良好的單調性,即服務節點的增減不會造成大量哈希重定位。一致性哈希算法就是這樣一種哈希方案。 一致性哈希算法算法簡述一致性哈希算法(Consistent Hashing)最早在論文《Consistent Hashing and Random Trees: Distributed Caching Protocols for Relieving Hot Spots on the World Wide Web》中被提出。簡單來說,一致性哈希將整個哈希值空間組織成一個虛擬的圓環,如假設某哈希函數H的值空間為0 – 232-1(即哈希值是一個32位無符號整形),整個哈希空間環如下: 哈希空間環
整個空間按順時針方向組織。0和232-1在零點中方向重合。
下一步將各個服務器使用H進行一個哈希,具體可以選擇服務器的ip或主機名作為關鍵字進行哈希,這樣每臺機器就能確定其在哈希環上的位置,這里假設將上文中三臺服務器使用ip地址哈希后在環空間的位置如下:
接下來使用如下算法定位數據訪問到相應服務器:將數據key使用相同的函數H計算出哈希值h,根據h確定此數據在環上的位置,從此位置沿環順時針“行走”,第一臺遇到的服務器就是其應該定位到的服務器。
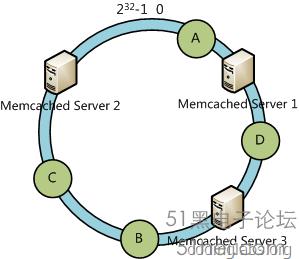
例如我們有A、B、C、D四個數據對象,經過哈希計算后,在環空間上的位置如下:
根據一致性哈希算法,數據A會被定為到Server 1上,D被定為到Server 3上,而B、C分別被定為到Server 2上。 容錯性與可擴展性分析下面分析一致性哈希算法的容錯性和可擴展性。現假設Server 3宕機了:
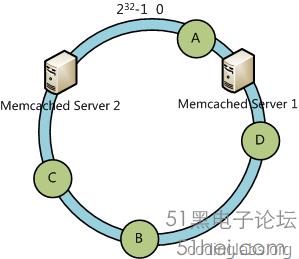
可以看到此時A、C、B不會受到影響,只有D節點被重定位到Server 2。一般的,在一致性哈希算法中,如果一臺服務器不可用,則受影響的數據僅僅是此服務器到其環空間中前一臺服務器(即順著逆時針方向行走遇到的第一臺服務器)之間數據,其它不會受到影響。
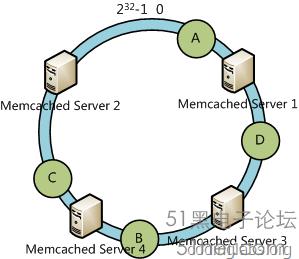
下面考慮另外一種情況,如果我們在系統中增加一臺服務器Memcached Server 4:
此時A、D、C不受影響,只有B需要重定位到新的Server 4。一般的,在一致性哈希算法中,如果增加一臺服務器,則受影響的數據僅僅是新服務器到其環空間中前一臺服務器(即順著逆時針方向行走遇到的第一臺服務器)之間數據,其它不會受到影響。
綜上所述,一致性哈希算法對于節點的增減都只需重定位環空間中的一小部分數據,具有較好的容錯性和可擴展性。 虛擬節點一致性哈希算法在服務節點太少時,容易因為節點分部不均勻而造成數據傾斜問題。例如我們的系統中有兩臺服務器,其環分布如下:
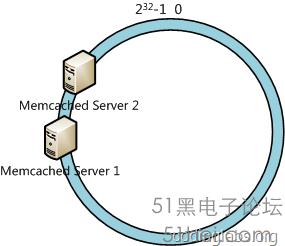
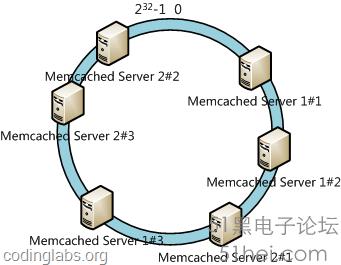
此時必然造成大量數據集中到Server 1上,而只有極少量會定位到Server 2上。為了解決這種數據傾斜問題,一致性哈希算法引入了虛擬節點機制,即對每一個服務節點計算多個哈希,每個計算結果位置都放置一個此服務節點,稱為虛擬節點。具體做法可以在服務器ip或主機名的后面增加編號來實現。例如上面的情況,我們決定為每臺服務器計算三個虛擬節點,于是可以分別計算“Memcached Server 1#1”、“Memcached Server 1#2”、“Memcached Server 1#3”、“Memcached Server 2#1”、“Memcached Server 2#2”、“Memcached Server 2#3”的哈希值,于是形成六個虛擬節點:
同時數據定位算法不變,只是多了一步虛擬節點到實際節點的映射,例如定位到“Memcached Server 1#1”、“Memcached Server 1#2”、“Memcached Server 1#3”三個虛擬節點的數據均定位到Server 1上。這樣就解決了服務節點少時數據傾斜的問題。在實際應用中,通常將虛擬節點數設置為32甚至更大,因此即使很少的服務節點也能做到相對均勻的數據分布。 總結目前一致性哈希基本成為了分布式系統組件的標準配置,例如Memcached的各種客戶端都提供內置的一致性哈希支持。本文只是簡要介紹了這個算法,更深入的內容可以參看論文《Consistent Hashing and Random Trees: Distributed Caching Protocols for Relieving Hot Spots on the World Wide Web》,同時提供一個C語言版本的實現供參考。
——–
作者已經在文章中介紹的比較清楚了,在這里補充下對“一致性哈希”這個名詞的簡單說明,在這個算法中就是指的機器標識符和存儲對象采用相同的哈希算法,從而把他們映射到同一個集合(即0-2^32-1的哈希環)。
 哈希空間環
哈希空間環