class memtest
{
public:
memtest(int _a, double _b) : a(_a), b(_b) {}
inline void print_addr(){
std::cout<<"Address of a and b is:\n\t\t"<<&a<<"\n\t\t" <<&b<<"\n";
}
inline void print_sta_mem(){
std::cout<<"Address of static member c is:\n\t\t"<<&c<<"\n";
}
private:
int a;
double b;
static int c;
};
int memtest::c = 8;
int main()
{
memtest m(1,1.0);
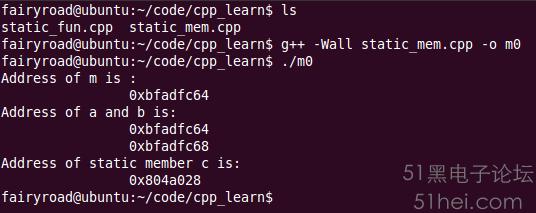
std::cout<<"Address of m is : \n\t\t"<< &m<<"\n";
m.print_addr();
m.print_sta_mem();
return 0;
}
在GCC4.4.5下編譯,運行,結果如下:
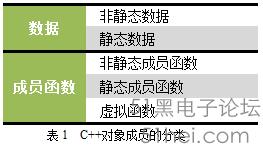
可以發現以下幾點:
1. 非靜態數據成員a的存儲地址就是從類的實例在內存中的地址中(本例中均為0xbfadfc64)開始的,之后的double b也緊隨其后,在內存中連續存儲;
2. 對于靜態數據成員c,則出現在了一個很“莫名其妙”的地址0x804a028上,與類的實例的地址看上去那是八竿子打不著;
其實不做這個測試,關于C++數據成員存儲的問題也都是C++ Programmer的常識,對于非靜態數據成員,一般編譯器都是按其在類中聲明的順序存儲,而且數據成員的起始地址就是類得實例在內存中的起始地址,這個在上面的測試中已經很明顯了。對非靜態數據成員的讀寫,我們可以這樣想,其實C++程序完全可以轉換成對應的C程序來編寫,有一些C++編譯器編譯C++程序時就是這樣做的。對非靜態數據成員的讀寫也可以借助這個等價的C程序來理解。考慮下面代碼段2:
// C++ code
struct foo{
public:
int get_data() const{ return data; }
void set_data(int _data){ data = _data;}
private:
int data;
};
foo f();
int d = f.get_data();
如果要你用C你會怎么實現呢?
// C code
struct foo{
int data;
};
int get_foo_data(const foo* pFoo){ return pFoo->data;}
void set_foo_data(foo* pFoo, int _data){ pFoo->data = _data;}
foo f;
f.data = 8;
foo* pF = &f;
int d = get_foo_data(pF);
在C程序中,我們要實現同樣的功能,必須是要往函數的參數列表中壓入一個指針作為實參。實際上C++在處理非靜態數據成員的時候也是這樣的,C++必須借助一個直接的或暗喻的實例指針來讀寫這些數據,這個指針,就是大名鼎鼎的 this指針。有了this指針,當我們要讀寫某個數據時,就可以借助一個簡單的指針運算,即this指針的地址加上該數據成員的偏移量,就可以實現讀寫了。這個偏移量由C++編譯器為我們計算出來。
對于靜態數據成員,如果在static_mem.cpp中加入下面一條語句:
std::cout<<”Size of class memtest is : ”<<sizeof(memtest)<<”\n”;
我們得到的輸出是:12。也就是說,class的大小僅僅是一個int 和一個double所占用的內存之和。這很簡單,也很明顯,靜態數據成員沒有存儲在類實例的地址空間中,它被C++編譯器弄到外面去了也就是程序的data segment中,因為靜態數據成員不在類的實例當中,所以也就不需要this指針的幫忙了。
1.2 單繼承與多重繼承的情況
由于我們還沒有討論類函數成員的情況,尤其,虛函數,在這一部分我們不考慮繼承中的多態問題,也就是說,這里的父類沒有虛函數——雖然這在實際中幾乎就是禁手。如此,我們的討論簡潔很多了。
在C++繼承模型中,一個子類的內存模型可以看成就是父類的各數據成員與自己新添加的數據成員的總和。請看下面的程序段3。
class father
{
public:
// constructors destructor
// access functions
// operations
private:
int age;
char sex;
std::string phone_number;
};
class child : public father
{
public:
// ...
private:
std::string twitter_url; // 兒子時髦,有推號
};
這里sizeof(father)和sizeof(child)分別是12和16(GCC 4.4.5)。先看sizeof(father)吧,int占4 bytes,char占1byte,std::string再占4 bytes,系統再將char圓整到4的倍數個字節,所以一共就是12 bytes了,對于child類,由于它僅僅引入了一個std::string,所以在12的基礎上加上std::string的4字節就是16字節了。
在單繼承不考慮多態的情況下,數據成員的布局是很簡單的。用一個圖來說明,如下。
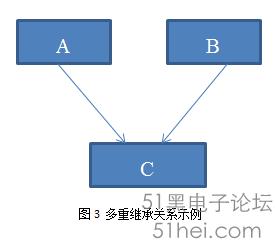
多重繼承一般都被公認為C++復雜性的證據之一,但是就數據成員而言,其實也很簡單,多重繼承的復雜性主要是指針類型轉換與環形繼承鏈的問題,這些內容都將在第二部分講述。
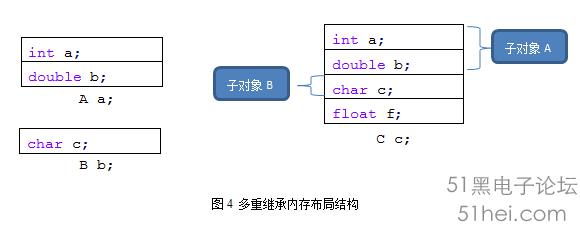
假設有下面三個類,如下面的程序段4所示,繼承結構關系如圖:
class A{
public:
// ...
private:
int a;
double b;
};
class B{
public:
// ...
private:
char c;
};
class C : public A, public B
public:
// ...
private:
float f;
};
那么,對應的內存布局就是圖4所示。
1.3 虛繼承
多重繼承的一個語意上的副作用就是它必須支持某種形式的共享子對象繼承,所謂共享,其實就是環形繼承鏈問題。最經典的例子就是標準庫本身的iostream繼承族。
class ios{...};
class istream : public ios {...};
class ostream : public ios {...};
class iostream : public istream, public ostream {...};
無論是istream還是ostream都含有一個ios類型的子對象。然而在iostream的對象布局中,我們只需要一個這樣的ios子對象就可以了,由此,新語法虛擬繼承就引入了。
虛擬繼承中,關于對象的數據成員內存布局問題有多種策略,在Inside the C++ Object Model中提出了三種流行的策略,而且Lippman寫此書的時候距今天已經很遙遠了,現代編譯器到底如何實現我也講不太清楚,等哪天去翻翻GCC的實現手冊再論,今天先前一筆債在這。
2、C++類函數成員的內存模型
2.1 關于C++指針類型
要理解好C++類的函數成員的內存模型,尤其是虛函數的實現機制,一定要對指針的概念非常清晰,指針是絕對的利器,無論是編寫代碼還是研究內部各種機制的實現機理,這是由計算機體系結構決定的。先給一段代碼,標記為代碼段5:
class foo{
//...
};
int a(1);
double b(2.0);
foo f = foo();