標題: 擁抱不確定性:深度學習還需一場分離冷凝機式的革命 [打印本頁]
作者: hubaba 時間: 2016-3-30 16:26
標題: 擁抱不確定性:深度學習還需一場分離冷凝機式的革命
本文作者為 Neil Lawrence,謝菲爾德大學機器學習和計算生物學教授。在
ODSC East(Open Data Science Conference East:開放數據科學大會(美國東部))上他詳盡地探討了機器學習的問題。
機器學習是一種數據驅動的人工智能研究方法。AlphaGo 通過許多局的自我對弈和觀察大量專業棋手的對弈歷史記錄來學習怎樣下圍棋。
看起來,讓計算機成為世界上最好的圍棋手只是一個時間問題。AlphaGo 通過機器學習擊敗了歐洲圍棋冠軍,這項技術是近來計算機視覺、語音識別和語言翻譯等人工智能領域內的重大進步的基礎。
最終的結果,當 AlphaGo 和那位歐洲圍棋冠軍開始第一場比賽時,它所下過的棋局數量就已經遠遠超過了任何人一輩子可能下過的棋局數量。自從那次獲勝之后,AlphaGo 還一直在積極學習提高自己。它日夜堅持不停地下棋,努力為與世界冠軍的對戰做準備。
我們的數據錯覺
[size=1em]這一現象并不僅限于 AlphaGo。在其它領域,我們(系統的)人類級別表現也受驚人的龐大數據驅動。我們的視覺系統為了識別物體需要遠比我們所需更多的有標記圖像,我們的語音系統為了理解話語需要遠比我們所需更多的話語,我們的翻譯系統需要的已翻譯樣本比一個人類能夠閱讀的還多。
[size=1em]
[size=1em]
△世界數據能力的增長評估
所以,盡管我們正在一些曾經被認為非常困難或不可能的任務中取得可觀的進步,但事實是這些進步更多是由更多的可用數據推動,不是來自算法的進步。事實上,當我們首次嘗試解決諸如物體識別和語言翻譯這樣的任務時,如果試圖將最新方法應用到那時擁有的數據量上,這些任務不可能得到解決。是數據爆炸讓它們易于處理。
蒸汽
[size=1em]這種情況讓我想起了工業革命的早期階段。Thomas Newcomen 生于英國西南部——一個自羅馬時代以來就以錫礦聞名的地區。礦需要將水抽出去使采礦不被影響。 1712 年,Newcomen 發明了蒸汽機來做這件事。他發明的引擎由一個位于鍋爐頂部的大型活塞組成。鍋爐產生的蒸汽交替填充這個活塞,然后通過直接注入水進行冷卻,進而引發運動。
[size=1em]
[size=1em]
煤炭
[size=1em]剛使用的時候,Newcomen 的引擎在他當地的錫礦里只有相對很小的作用,如此低效以至于毫不實用。但是,它們卻在煤田中得到了廣泛的使用,因為在煤田里可以很容易補充燃料。這多少讓我想起今天的情形:主要互聯網公司可以通過當前一代推理引擎獲利,因為這些公司相當于當年的煤田,擁有大量可供使用的數據。
[size=1em]
醫療應用
[size=1em]目前,我們正在錯失(這一領域的)錫礦以及任何其他礦藏的等價物。在醫藥等應用領域,我們面臨不少困難,首先是因為:系統的復雜性遠遠高于語音、視覺、甚至圍棋游戲。我們的干預通常是在生物化學層面,然而,干預的臨床表現卻發生在全球健康層面。
對于罕見或復雜的疾病——那些由壞境和基因原因共同導致的疾病,使用當前這套低效模型,我們將永遠不會獲得足夠的數據,讓這些復雜模型學習早期診斷和治療所需的知識。
分離冷凝器
[size=1em]在我們腦海里,蒸汽機與詹姆斯·瓦特的相關度要高得多,瓦特通過引入分離冷凝器讓蒸汽機變得實用。他沒有直接將水注入到汽缸中,而是將蒸汽吸出汽缸后分開冷卻它。
[size=1em]
[size=1em]
[size=1em]△詹姆斯·瓦特帶有分離冷凝器的蒸汽機的結構
[size=1em]
[size=1em]這種設計更加有效,因為汽缸本身再也不用經歷加熱和冷卻的循環了。由此導致了效率的倍增,使蒸汽機變得實用;它不再只被用于康沃爾的錫礦,也被用在了鐵路和牽引引擎上。
[size=1em]
智能
[size=1em]我對智能的定義是:使用信息,節省能源。
智能決策的含義是,消化事實,做出決定,這個決定減少了與行動相關的支出(較之沒有掌握哪些事實的情況下)。根據這一定義,通過生成決定節省能源或者使用更少的信息,我們就能變得更加智能。
在非常現實的意義上,目前還存在數據效率赤字問題,赤字和當年 Newcomen 的引擎效率赤字一樣大。機器學習需要它的分離冷凝器這一契機。在數據效率上,我們需要一次瓦特的分離冷凝器一樣的革命。
[size=1em]
函數組合(Function Composition)和深度學習
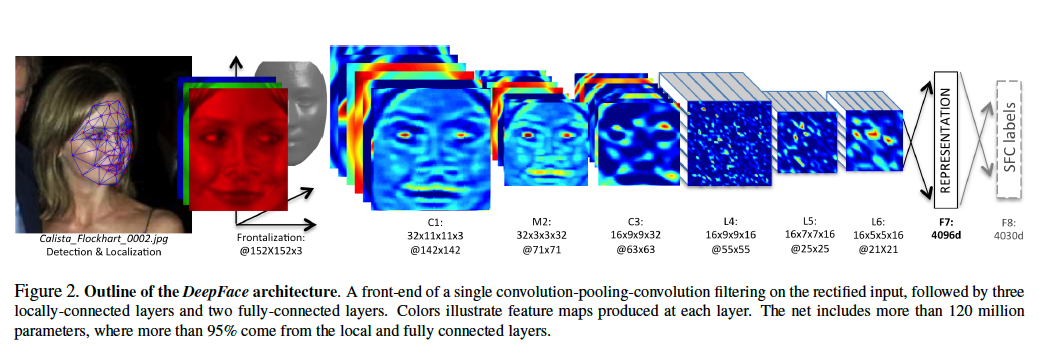 △DeepFace 的架構,該識別系統來自 Facebook 的論文
△DeepFace 的架構,該識別系統來自 Facebook 的論文[size=1em]
[size=1em]在數學上,我們有時候可以將一個函數看作是一個確定過程(deterministic process)。因此,我們能將深度學習視為確定過程的組合。每個過程組合起來,創造出更加復雜的過程。對過程呈現數據(presentation of data to the process)能讓我們運用一組轉換獲得一個結果。上面的例子來自于 Facebook 的DeepFace 算法,其目標是區分所給圖片是否是 Calista Flockhart 的臉。
[size=1em]
在機器學習中,這被稱為深度學習。對于一些作者而言,這與大腦有關或是一種思考人工智能的基本方式,但是,我們可以簡單將其看做是一種明智的想法,將一系列簡單變換運用于圖片,構建復雜轉換。
現在機器學習的難題是怎么決定這些轉換的應該是什么樣的。每一個更簡單的確定轉換,確實可以有許多參數。在 DeepFace 的案例中總共有超過 1.2 億個參數。
當我們想到深度學習時,就能想到任何給定數據點通過決定過程,就像小球穿過早期的彈球機(Pachinko 機)。每一層的欄針等同于深度模型的每一層。
[size=1em]

△彈球機
機器學習的目的是重構這些欄針的配置,使 Calista 的臉可被正確探測到。可以將臉看作是以一組初始條件,而臉通過每一個過程后都以修改過的形式出現。推理的任務是確保正確的初始條件集合能導向正確的結論。
我們的深度學習模型就像 Pachinko 機,但我們所能控制的只是欄針的位置。深度學習的目的是移動這些欄針的位置使其在正確的初始條件集合下(如我們比喻中的圖像所示)可以得到正確結果。
該模型的參數有時被稱作是網絡權重(network weight)。它們就像是欄針的位置。所以我們可以將 DeepFace 看作是有 1.2 億個欄針的 Pachinko 機。
我們可以將網絡關于某個特定模式所「想到」的內容看作是小球穿過網絡時的左右位置。當然在現實中,在欄針的每一層,這個「想法」只有一個值。它是一維的。真正的深度網絡擁有許許多多的維數,所以它就像一臺欄針位于高維空間的 Pachinko 機,通常這被稱作超維空間(hyper-space),這意味著該網絡的「想法」有更高維數而且更為復雜。
確定過程
今天占主導地位的技術假定,球應該通過固定的路徑通過網絡。球在彈珠機任意層的位置被稱為該層的激活。當球落下時,欄針決定了它的位置。在理論上,我們可以精準地說出球在任何時間的位置,因為彈珠機的每層都只涉及一個球撞擊欄針:這是一個確定過程。
彈珠機的游戲包括試圖通過用正確速度使用柱塞開球來贏得高分。這很難做到,因為分數對起點的位置非常敏感。但實際上,這場游戲是「理解」球的初始速度,并通過給它打分數來分類。
面臨的挑戰是優化機器的內部結構,使它在正確的初始條件下給出正確的答案 (或標簽)。然而,要做到這一點,需要探索我們想要測試的全部初始條件:并且針對數量肯定會很多的圖片。
卷積神經網絡 (convolutional neural networks) 的巧妙部分是為機器建構第一組層級,使諸如圖片中「不變性」的這些方面更加容易學習。 不變性是指在圖片里,不論旋轉還是移動,一張臉都是相同一張臉的概念。我們的大腦很容易明白這點,但不變性很難被電腦理解。深度神經網絡則通彈球機第一部分結構的巧妙設計來實現這一點。
絕大多數學習的方法是,在彈球機的頂部呈現一個圖像,看球在哪里彈出。如果球在錯誤的地方彈出,所有的欄針將稍作移動,試圖讓球多出現在正確的位置。
問題
如果你用各種不同存在微妙變化的方式扔球,這個方法會很好用。你最終可以讓系統正確。但是,如果你只有有限的扔球次數,怎么辦?
你已經知道,輸入值的微小變化可以解釋終端相當大的變化。彈球機很復雜,并對輸入值的微小變化敏感。但是,要正確確定這些敏感點需要大量的數據。
另一種方法是,確保機器對初始條件的小變化保持強健 。做到這一點需要隨機性。不要把機器建模為一組確定過程——其中球每次以相同的方式掉下,你要把機器建模成一組分層的隨機過程 (stochastic processes) 。
接受在頂部扔球方式上的小變化,意味著我們其實不知道球在任何時間應該在哪,因為我們無法準確知道欄針的位置,或者球的初始狀態。進一步,我們永遠不會有足夠的數據來探索不同所有這些不同的狀態。
隨機過程構成

我們通過考慮球在機器上所有可能經過的路徑,獲得更多有效的學習方法。不要鼓勵機器只盯著一條路徑,我們鼓勵所有通往正確結果的路徑。
考慮所有路徑可以使模型對輸入上的小變化上更健壯 (robust)。試想導航通過有許多不同路徑的森林。這兩種方法之間的區別就像是確保有一個標記完善,通往正確目的地的路徑,或者有一組不同的路徑帶你去正確目的地。
這是一個系統的路徑積分解釋。我們設計了一個系統,在其中考慮所有球可能在系統中通過的路徑。更奇怪的是,我們考慮了應該同時帶你抵達那里的欄針的所有可能配置。
這聽起來很困難,但在某一類過程中(例如高斯過程)中確實易于處理 。所以,如果我們用高斯過程做出每一層,就能處理那個組成部分本身。但是,我希望我們的深度模型有很多這樣的層在一起,這樣我們可以為復雜事情建模。要做到這點,我們組成隨機模型:有效地將這些層再一次疊在一起,就像在彈球機里一樣。當我們把簡單的流程堆疊在一起,會有很多關于如何做數學并且執行相應的算法等挑戰性的問題。
我們知道,對于非常大的數據來說,我們所提出的隨機方法瓦解了深度學習的確定性方法。因為在這些情況下,路徑積分瓦解成單個最有可能的路徑,隨著我們獲得更多的數據,它也變得確定。但是,對于低數據(low data),我們可以實現更好的效率。
算法的挑戰
主要算法挑戰在于,路徑積分解法(solution of the path integral)要比僅僅找到最佳路徑要有挑戰性地多。最佳路徑僅需我們做出區分,但是,瀏覽所有路徑需要集成,這是一個更大的挑戰:特別是當在我們所需的Pachinko機的「超維空間」版本中執行這一操作時。這一數學操作就是所謂的卷積,而且也只可能針對簡單系統進行精確操作。
前行之路
熱動力學花了好長時間才跟上瓦特分離冷凝器的應用步伐,但是,完全理解熱動力學卻對現代世界的發展,至關重要。結果表明,我們實現高效智能所需的路徑積分和熱動力理論之間存在強數學關系,后者被用來解釋為什么瓦特的分離冷凝器讓蒸汽機引擎更有效率。
一個向前的數學方法被稱為「變分法」。包括將不同積分轉為不同但更加簡單的優化問題。這個方法不是很準確,但是會時常比確定性方案要好得多。這被稱為變分學習。如果我們建造有效的變分算法 ,就能在小數據集上實現深度模型。
最終仔細分析熱能理論基礎的也是變分方法。從這種研究中出現了一些概念,比如熵。
我們知道一件事,通過熱動能的類比,最好讓你的Pachinko機「盡可能地熱」(或者,盡可能不確定)同時約束它按平均值給出正確答案。那會讓它對輸入的變化更加強健。物理學上,這一方法被稱為最大熵原理。
下一代數學高效學習方法依賴我們研發出新算法,正好通過模型傳播隨機性或不確定性。
有一個大型并還在不斷變大的研究人員社區,他們實現并推到這些算法。他們多采用數學的方法而不是標準的方法,不過,沒有他們,我們當中的許多人會處在當年康沃爾鋅礦工的位置:因為我們自己缺乏數據效率,因此無法受益于廣泛的數據供應。
因此,最終,我們的效率要求歸結為處理不確定的問題。瓦特的效率成果來自確保引擎活塞盡可能維持熱度。因為關閉熱蒸汽的活塞被吸出并分離冷凝。這能夠讓活塞熱運行,傳遞必需的效率。
在深度學習的概率和隨機方法上,我們必須施展同樣的竅門。模型本身需要盡可能地維持熱度:然后,當數據不足以約束擁抱不確定所需的模型的運行時,別熄滅它。當機器循環通過數據時,我們的分離冷凝機將允許學習機器中保持高溫。那會確保運行合理方式的全部空間得到開發,并且我們的推理也會保持必要的強健性,即使當數據稀少時。
?本文由機器之心編譯
| 歡迎光臨 (http://www.zg4o1577.cn/bbs/) |
Powered by Discuz! X3.1 |
主站蜘蛛池模板:
日韩三|
亚洲一区二区三区四区在线观看
|
亚洲国产欧美在线
|
日韩一区二区三区在线视频
|
色视频www在线播放国产人成
|
曰批视频在线观看
|
久草资源在线视频
|
欧美三级在线
|
国产欧美在线一区二区
|
国产在线播放一区二区三区
|
午夜网
|
国产精品看片
|
国产精品片
|
亚洲精品成人
|
午夜精品一区二区三区在线
|
国产精品123区
|
99reav|
国产丝袜一区二区三区免费视频
|
久久av影院|
亚洲高清在线免费观看
|
国产一区二区三区色淫影院
|
亚洲精品一区二区网址
|
久久成人精品一区二区三区
|
日韩一区二区黄色片
|
一区二区三区精品
|
av网站在线看|
91精品国产高清一区二区三区
|
chengrenzaixian|
日韩中文字幕av
|
欧美日韩在线不卡
|
av中文字幕网
|
免费在线观看av片
|
99精品免费在线观看
|
国产精品久久久久久亚洲调教
|
91免费在线
|
黄网站免费在线
|
精品国产一区二区三区久久久蜜月
|
精品亚洲第一
|
中文字幕在线观看视频一区
|
蜜桃免费一区二区三区
|
免费一级大片
|