�������ߞ� Neil Lawrence���x�Ơ��´�W(xu��)�C(j��)���W(xu��)��(x��)��Ӌ������W(xu��)���ڡ���
ODSC East��Open Data Science Conference East���_�Ŕ�(sh��)��(j��)�ƌW(xu��)����������|����������Ԕ�M��̽ӑ�˙C(j��)���W(xu��)��(x��)�Ć��}��
�C(j��)���W(xu��)��(x��)��һ�N��(sh��)��(j��)�(q��)�ӵ��˹������о�������AlphaGo ͨ�^�S��ֵ����Ҍ��ĺ��^��������I(y��)���ֵČ��Ěvʷӛ䛁�W(xu��)��(x��)�������塣
��������Ӌ��C(j��)�ɞ���������õć�����ֻ��һ���r�g���}��AlphaGo ͨ�^�C(j��)���W(xu��)��(x��)�����˚W�އ����܊���@헼��g(sh��)�ǽ���Ӌ��C(j��)ҕ�X���Z���R�e���Z�Է��g���˹������I(l��ng)���(n��i)���ش��M(j��n)���Ļ��A(ch��)��
��K�ĽY(ji��)������(d��ng) AlphaGo ����λ�W�އ����܊�_ʼ��һ����ِ�r���������^�����?j��n)?sh��)�����ѽ�(j��ng)�h(yu��n)�h(yu��n)���^���κ���һ݅�ӿ������^�����?j��n)?sh��)�����ԏ��ǴΫ@��֮��AlphaGo ߀һֱ�ڷe�O�W(xu��)��(x��)����Լ�������ҹ�Գֲ�ͣ�����壬Ŭ�����c�����܊�Č���(zh��n)����(zh��n)�䡣
�҂��Ĕ�(sh��)��(j��)�e�X
[size=1em]�@һ�F(xi��n)���H���� AlphaGo���������I(l��ng)���҂���ϵ�y(t��ng)�ģ�����e���F(xi��n)Ҳ���@�˵�����(sh��)��(j��)�(q��)�ӡ��҂���ҕ�Xϵ�y(t��ng)�����R�e���w��Ҫ�h(yu��n)���҂����������И�(bi��o)ӛ�D���҂����Z��ϵ�y(t��ng)��������Ԓ�Z��Ҫ�h(yu��n)���҂���������Ԓ�Z���҂��ķ��gϵ�y(t��ng)��Ҫ���ѷ��g�ӱ���һ������܉���x��߀�ࡣ [size=1em]
[size=1em]
�����电(sh��)��(j��)���������L�u��
���ԣ��M���҂�����һЩ����(j��ng)���J(r��n)��dz����y���ܵ��΄�(w��)��ȡ�ÿ��^���M(j��n)�����������@Щ�M(j��n)���������ɸ���Ŀ��Ô�(sh��)��(j��)�Ƅӣ����ǁ����㷨���M(j��n)�������ϣ���(d��ng)�҂��״·Lԇ��Q�T�����w�R�e���Z�Է��g�@�ӵ��΄�(w��)�r�����ԇ�D�����·�����(y��ng)�õ��Ǖr���еĔ�(sh��)��(j��)���ϣ��@Щ�΄�(w��)�����ܵõ���Q���ǔ�(sh��)��(j��)��ը��������̎����
����
[size=1em]�@�N��r�������˹��I(y��)�����������A�Ρ�Thomas Newcomen ����Ӣ�����ϲ�����һ�����_�R�r���ԁ������a�V���ĵ^(q��)���V��Ҫ��ˮ���ȥʹ�ɵV����Ӱ푡� 1712 �꣬Newcomen �l(f��)���������C(j��)�����@���¡����l(f��)����������һ��λ��偠t픲��Ĵ��ͻ����M�ɡ�偠t�a(ch��n)����������������@��������Ȼ��ͨ�^ֱ��ע��ˮ�M(j��n)����s���M(j��n)�����l(f��)�\(y��n)�ӡ� [size=1em]
[size=1em] ú̿
[size=1em]��ʹ�õĕr��Newcomen ������������(d��ng)?sh��)ص��a�V��ֻ��������С�����ã���˵�Ч�����ں������á����ǣ������s��ú���еõ��ˏV����ʹ�ã������ú������Ժ������a(b��)��ȼ�ϡ��@�����������������Σ���Ҫ��(li��n)�W(w��ng)��˾����ͨ�^��(d��ng)ǰһ����������@��������@Щ��˾�ஔ(d��ng)�ڮ�(d��ng)���ú����д����ɹ�ʹ�õĔ�(sh��)��(j��)�� [size=1em]
�t(y��)����(y��ng)��
[size=1em]Ŀǰ���҂������eʧ���@һ�I(l��ng)��ģ��a�V�Լ��κ������V�صĵȃr����t(y��)ˎ�ȑ�(y��ng)���I(l��ng)���҂����R�������y����������飺ϵ�y(t��ng)�ď�(f��)�s���h(yu��n)�h(yu��n)�����Z����ҕ�X�����������Α��҂��ĸ��A(y��)ͨ���������ﻯ�W(xu��)���棬Ȼ�������A(y��)���R�����F(xi��n)�s�l(f��)����ȫ�����档
���ں�Ҋ���(f��)�s�ļ���������Щ�ɉľ��ͻ���ԭ��ͬ��(d��o)�µļ�����ʹ�î�(d��ng)ǰ�@��Чģ�ͣ��҂������h(yu��n)�����@�����Ĕ�(sh��)��(j��)���@Щ��(f��)�sģ�͌W(xu��)��(x��)�����\����ί������֪�R��
���x������
[size=1em]���҂��X��������C(j��)�cղķ˹�����ص����P(gu��n)��Ҫ�ߵö࣬����ͨ�^������x�����������C(j��)׃�Ì��á����]��ֱ�ӌ�ˮע�뵽�����У����nj���������������_��s���� [size=1em]
[size=1em] [size=1em]��ղķ˹�����؎��з��x�������������C(j��)�ĽY(ji��)��(g��u) [size=1em]
[size=1em]�@�N�O(sh��)Ӌ������Ч��������ױ�����Ҳ���ý�(j��ng)�v�ӟ����s��ѭ�h(hu��n)�ˡ��ɴˌ�(d��o)����Ч�ʵı�����ʹ�����C(j��)׃�Ì��ã�������ֻ�����ڿ��֠����a�V��Ҳ���������F·�͠��������ϡ� [size=1em]
����
[size=1em]�Ҍ����ܵĶ��x�ǣ�ʹ����Ϣ����(ji��)ʡ��Դ��
���ܛQ�ߵĺ��x�ǣ��������������Q�����@���Q���p�����c�Є����P(gu��n)��֧�����^֮�]��������Щ������r�£�������(j��)�@һ���x��ͨ�^���ɛQ����(ji��)ʡ��Դ����ʹ�ø��ٵ���Ϣ���҂�����׃�ø������ܡ�
�ڷdz��F(xi��n)�������x�ϣ�Ŀǰ߀���ڔ�(sh��)��(j��)Ч�ʳ��ֆ��}�����ֺͮ�(d��ng)�� Newcomen ������Ч�ʳ���һ�ӴC(j��)���W(xu��)��(x��)��Ҫ���ķ��x�������@һ���C(j��)���ڔ�(sh��)��(j��)Ч���ϣ��҂���Ҫһ�����صķ��x������һ�ӵĸ����� [size=1em]
����(sh��)�M�ϣ�Function Composition������ȌW(xu��)��(x��)
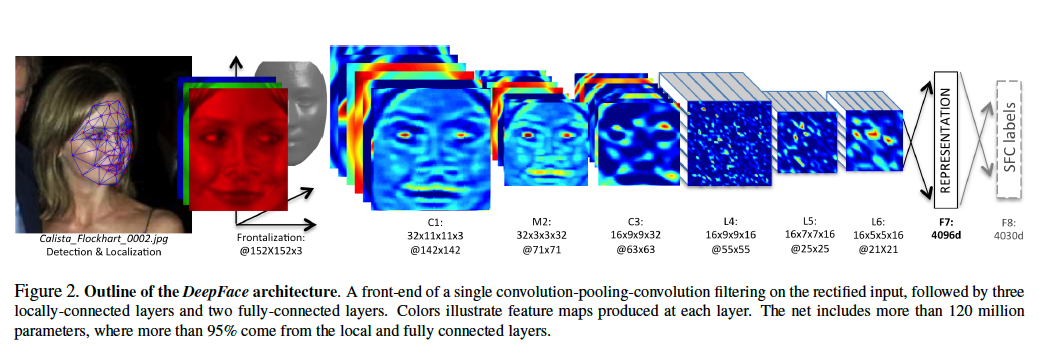 ��DeepFace �ļܘ�(g��u)��ԓ�R�eϵ�y(t��ng)���� Facebook ��Փ��
��DeepFace �ļܘ�(g��u)��ԓ�R�eϵ�y(t��ng)���� Facebook ��Փ��[size=1em]
[size=1em]�ڔ�(sh��)�W(xu��)�ϣ��҂��Еr����Ԍ�һ������(sh��)������һ���_���^�̣�deterministic process������ˣ��҂��܌���ȌW(xu��)��(x��)ҕ��_���^�̵ĽM�ϡ�ÿ���^�̽M����������(chu��ng)������ӏ�(f��)�s���^�̡����^�̳ʬF(xi��n)��(sh��)��(j��)��presentation of data to the process�����҂��\(y��n)��һ�M�D(zhu��n)�Q�@��һ���Y(ji��)������������Ӂ����� Facebook ��DeepFace �㷨����Ŀ��(bi��o)�Dž^(q��)�����o�DƬ�Ƿ��� Calista Flockhart ��Ę��
[size=1em]
�ڙC(j��)���W(xu��)��(x��)�У��@���Q����ȌW(xu��)��(x��)������һЩ���߶��ԣ��@�c���X���P(gu��n)����һ�N˼���˹����ܵĻ�����ʽ�����ǣ��҂����Ժ��Ό��俴����һ�N���ǵ��뷨����һϵ�к���׃�Q�\(y��n)���ڈDƬ����(g��u)����(f��)�s�D(zhu��n)�Q��
�F(xi��n)�ڙC(j��)���W(xu��)��(x��)���y�}����ô�Q���@Щ�D(zhu��n)�Q�đ�(y��ng)ԓ��ʲô�ӵġ�ÿһ�������εĴ_���D(zhu��n)�Q���_���������S������(sh��)���� DeepFace �İ����п����г��^ 1.2 �|������(sh��)��
��(d��ng)�҂��뵽��ȌW(xu��)��(x��)�r�������뵽�κνo����(sh��)��(j��)�c(di��n)ͨ�^�Q���^�̣�����С���^���ڵď���C(j��)��Pachinko �C(j��)����ÿһ�ӵę�ᘵ�ͬ�����ģ�͵�ÿһ�ӡ� [size=1em]

������C(j��)
�C(j��)���W(xu��)��(x��)��Ŀ�����ؘ�(g��u)�@Щ��ᘵ����ã�ʹ Calista ��Ę�ɱ����_̽�y�������Ԍ�Ę��������һ�M��ʼ�l������Ęͨ�^ÿһ���^�̺������^����ʽ���F(xi��n)���������΄�(w��)�Ǵ_�����_�ij�ʼ�l�������܌�(d��o)�����_�ĽY(ji��)Փ��
�҂�����ȌW(xu��)��(x��)ģ�;��� Pachinko �C(j��)�����҂����ܿ��Ƶ�ֻ�Ǚ�ᘵ�λ�á���ȌW(xu��)��(x��)��Ŀ�����Ƅ��@Щ��ᘵ�λ��ʹ�������_�ij�ʼ�l�������£����҂������еĈD����ʾ�����Եõ����_�Y(ji��)����
ԓģ�͵ą���(sh��)�Еr���Q���ǾW(w��ng)�j(lu��)��(qu��n)�أ�network weight�������������Ǚ�ᘵ�λ�á������҂����Ԍ� DeepFace �������� 1.2 �|����ᘵ� Pachinko �C(j��)��
�҂����Ԍ��W(w��ng)�j(lu��)�P(gu��n)��ij���ض�ģʽ�����뵽���ă�(n��i)�ݿ�����С���^�W(w��ng)�j(lu��)�r������λ�á���(d��ng)Ȼ�ڬF(xi��n)���У��ڙ�ᘵ�ÿһ�ӣ��@�����뷨��ֻ��һ��ֵ������һ�S�ġ���������ȾW(w��ng)�j(lu��)�����S�S���ľS��(sh��)������������һ�_���λ�ڸ߾S���g�� Pachinko �C(j��)��ͨ���@���Q�����S���g��hyper-space�����@��ζ��ԓ�W(w��ng)�j(lu��)�ġ��뷨���и��߾S��(sh��)���Ҹ����(f��)�s��
�_���^��
����ռ����(d��o)��λ�ļ��g(sh��)�ٶ�����(y��ng)ԓͨ�^�̶���·��ͨ�^�W(w��ng)�j(lu��)�����ڏ���C(j��)����ӵ�λ�ñ��Q��ԓ�ӵļ����(d��ng)�����r����ᘛQ��������λ�á�����Փ�ϣ��҂����Ծ���(zh��n)���f�������κΕr�g��λ�ã���鏗��C(j��)��ÿ�Ӷ�ֻ�漰һ����ײ����ᘣ��@��һ���_���^�̡�
����C(j��)���Α����ԇ�Dͨ�^�����_�ٶ�ʹ�������_����A�ø߷֡��@���y����������?j��n)?sh��)�����c(di��n)��λ�÷dz����С������H�ϣ��@���Α��ǡ����⡹��ij�ʼ�ٶȣ���ͨ�^�o�����?j��n)?sh��)�����
���R������(zh��n)�ǃ�(y��u)���C(j��)���ă�(n��i)���Y(ji��)��(g��u)��ʹ�������_�ij�ʼ�l���½o�����_�Ĵ� (���(bi��o)��)��Ȼ����Ҫ�����@һ�c(di��n)����Ҫ̽���҂���Ҫ�yԇ��ȫ����ʼ�l��������ᘌ���(sh��)���϶����ܶ�ĈDƬ��
���e��(j��ng)�W(w��ng)�j(lu��) (convolutional neural networks) ��������Ǟ�C(j��)������(g��u)��һ�M�Ӽ���ʹ�T��DƬ�С���׃�ԡ����@Щ����������W(xu��)��(x��)�� ��׃����ָ�ڈDƬ���Փ���D(zhu��n)߀���Ƅӣ�һ��Ę������ͬһ��Ę�ĸ���҂��Ĵ��X�����������@�c(di��n)������׃�Ժ��y����X���⡣�����(j��ng)�W(w��ng)�j(lu��)�tͨ����C(j��)��һ���ֽY(ji��)��(g��u)�������O(sh��)Ӌ�팍�F(xi��n)�@һ�c(di��n)��
�^�����(sh��)�W(xu��)��(x��)�ķ����ǣ��ڏ���C(j��)��픲��ʬF(xi��n)һ���D���������������������e�`�ĵط����������еę�ᘌ������Ƅӣ�ԇ�D�����F(xi��n)�����_��λ�á�
���}
������ø��N��ͬ������׃���ķ�ʽ�����@���������ܺ��á�����K����ϵ�y(t��ng)���_�����ǣ������ֻ����������Δ�(sh��)����ô�k��
���ѽ�(j��ng)֪����ݔ��ֵ��С׃�����Խ�ጽK���ஔ(d��ng)���׃��������C(j��)��(f��)�s������ݔ��ֵ��С׃�����С����ǣ�Ҫ���_�_���@Щ�����c(di��n)��Ҫ�����Ĕ�(sh��)��(j��)��
��һ�N�����ǣ��_���C(j��)������ʼ�l����С׃�����֏�(qi��ng)�� �������@һ�c(di��n)��Ҫ�S�C(j��)�ԡ���Ҫ�љC(j��)����ģ��һ�M�_���^�̡���������ÿ������ͬ�ķ�ʽ���£���Ҫ�љC(j��)����ģ��һ�M�ӵ��S�C(j��)�^�� (stochastic processes) ��
������픲�����ʽ�ϵ�С׃������ζ���҂��䌍��֪�������κΕr�g��(y��ng)ԓ���ģ�����҂��o����(zh��n)�_֪����ᘵ�λ�ã�������ij�ʼ��B(t��i)���M(j��n)һ�����҂����h(yu��n)���������Ĕ�(sh��)��(j��)��̽����ͬ�����@Щ��ͬ�Ġ�B(t��i)��
�S�C(j��)�^�̘�(g��u)��

�҂�ͨ�^���]���ڙC(j��)�������п��ܽ�(j��ng)�^��·�����@�ø�����Ч�ČW(xu��)��(x��)��������Ҫ�Ą�C(j��)��ֻ����һ�l·�����҂��Ą�����ͨ�����_�Y(ji��)����·����
���]����·������ʹģ�͌�ݔ���ϵ�С׃���ϸ����� (robust)��ԇ�댧(d��o)��ͨ�^���S�ͬ·����ɭ�֡��@�ɷN����֮�g�ą^(q��)�e�����Ǵ_����һ����(bi��o)ӛ���ƣ�ͨ�����_Ŀ�ĵص�·����������һ�M��ͬ��·������ȥ���_Ŀ�ĵء�
�@��һ��ϵ�y(t��ng)��·���e�ֽ�ጡ��҂��O(sh��)Ӌ��һ��ϵ�y(t��ng)�������п��]�����������ϵ�y(t��ng)��ͨ�^��·��������ֵ��ǣ��҂����]�ˑ�(y��ng)ԓͬ�r������_(d��)����ę�ᘵ����п������á�
�@ ���������y������ijһ��^����(�����˹�^��)�д_������̎�� �����ԣ�����҂��ø�˹�^������ÿһ�ӣ�����̎���ǂ��M�ɲ��ֱ��������ǣ���ϣ���҂������ģ���кܶ��@�ӵČ���һ���@���҂����Ԟ��(f��)�s���齨ģ��Ҫ�����@�c(di��n)���҂��M���S�C(j��)ģ�ͣ���Ч�،��@Щ����һ�ίB��һ�𣬾����ڏ���C(j��)��һ�ӡ���(d��ng)�҂��Ѻ��ε����̶ѯB��һ�𣬕��кܶ��P(gu��n)���������(sh��)�W(xu��)���҈�(zh��)������(y��ng)���㷨������(zh��n)�ԵĆ��}��
�҂�֪�������ڷdz���Ĕ�(sh��)��(j��)���f���҂���������S�C(j��)�����߽�����ȌW(xu��)��(x��)�Ĵ_���Է�����������@Щ��r�£�·���e���߽�Ɇ����п��ܵ�·�����S���҂��@�ø���Ĕ�(sh��)��(j��)����Ҳ׃�ô_�������ǣ����ڵ͔�(sh��)��(j��)��low data�����҂����Ԍ��F(xi��n)���õ�Ч�ʡ�
�㷨������(zh��n)
��Ҫ�㷨����(zh��n)���ڣ�·���e�ֽⷨ��solution of the path integral��Ҫ�ȃH�H�ҵ����·��Ҫ������(zh��n)�Եضࡣ���·���H���҂������^(q��)�֣����ǣ��g�[����·����Ҫ���ɣ��@��һ�����������(zh��n)���e�Ǯ�(d��ng)���҂������Pachinko�C(j��)�ġ����S���g���汾�Ј�(zh��)���@һ�����r���@һ��(sh��)�W(xu��)�����������^�ľ��e������Ҳֻ����ᘌ�����ϵ�y(t��ng)�M(j��n)�о��_������
ǰ��֮·
������W(xu��)���˺��L�r�g�Ÿ������ط��x�������đ�(y��ng)�ò��������ǣ���ȫ���������W(xu��)�s���F(xi��n)������İl(f��)չ�����P(gu��n)��Ҫ���Y(ji��)���������҂����F(xi��n)��Ч���������·���e�ֺ͟������Փ֮�g���ڏ�(qi��ng)��(sh��)�W(xu��)�P(gu��n)ϵ�����߱��Á���ጞ�ʲô���صķ��x�����������C(j��)�������Ч�ʡ�
һ����ǰ�Ĕ�(sh��)�W(xu��)�������Q�顸׃�ַ�������������ͬ�e���D(zhu��n)�鲻ͬ�����Ӻ��εă�(y��u)�����}���@���������Ǻܜ�(zh��n)�_�����Ǖ��r���ȴ_���Է���Ҫ�õöࡣ�@���Q��׃�W(xu��)��(x��)������҂�������Ч��׃���㷨 ��������С��(sh��)��(j��)���ό��F(xi��n)���ģ�͡�
��K�м�(x��)����������Փ���A(ch��)��Ҳ��׃�ַ��������@�N�о��г��F(xi��n)��һЩ��������ء�
�҂�֪��һ���£�ͨ�^����ܵ�ȣ�������Pachinko�C(j��)���M���ܵ�?z��)�����ߣ��M���ܲ��_����ͬ�r�s������ƽ��ֵ�o�����_�𰸡��Ǖ�����ݔ���׃�����ӏ�(qi��ng)��������W(xu��)�ϣ��@һ�������Q�������ԭ����
��һ����(sh��)�W(xu��)��Ч�W(xu��)��(x��)������ه�҂��аl(f��)�����㷨������ͨ�^ģ�͂����S�C(j��)�Ի_���ԡ�
��һ�����Ͳ�߀�ڲ���׃����о��ˆT��^(q��)���������F(xi��n)���Ƶ��@Щ�㷨����������Ô�(sh��)�W(xu��)�ķ��������ǘ�(bi��o)��(zh��n)�ķ��������^���]���������҂���(d��ng)�е��S���˕�̎�ڮ�(d��ng)�꿵�֠��\�V����λ�ã�����҂��Լ�ȱ����(sh��)��(j��)Ч�ʣ���˟o�������ڏV���Ĕ�(sh��)��(j��)����(y��ng)��
��ˣ���K���҂���Ч��Ҫ��w�Y(ji��)��̎�����_���Ć��}�����ص�Ч�ʳɹ����Դ_����������M���ܾS�֟�ȡ�����P(gu��n)�]�������Ļ��������������x�������@�܉��������\(y��n)�У����f�����Ч�ʡ�
����ȌW(xu��)��(x��)�ĸ��ʺ��S�C(j��)�����ϣ��҂����ʩչͬ�ӵĸ[�T��ģ�ͱ�����Ҫ�M���ܵؾS�֟�ȣ�Ȼ��(d��ng)��(sh��)��(j��)�����Լs���������_�������ģ�͵��\(y��n)�Еr���eϨ��������(d��ng)�C(j��)��ѭ�h(hu��n)ͨ�^��(sh��)��(j��)�r���҂��ķ��x�����C(j��)�����S�W(xu��)��(x��)�C(j��)���б��ָߜء��Ǖ��_���\(y��n)�к�����ʽ��ȫ�����g�õ��_�l(f��)�������҂�������Ҳ�����ֱ�Ҫ�ď�(qi��ng)���ԣ���ʹ��(d��ng)��(sh��)��(j��)ϡ�ٕr��
?�����əC(j��)��֮�ľ��g
| 




 ����TQQ:125739409;���g(sh��)����QQȺ281945664
����TQQ:125739409;���g(sh��)����QQȺ281945664




 QQ���Ѻ�Ⱥ
QQ���Ѻ�Ⱥ QQ���g
QQ���g �vӍ��
�vӍ�� �vӍ����
�vӍ���� �ղ�
�ղ� ����
���� �
� ��
��